In the last part we have seen that Tupper encrypts “.txt” files using RSA and “.pdf” files using a xor and custom key schedule. In this part we will write decryption scripts to recover encrypted files because Tupper doesn’t provide any decryption function.
Breaking the encryptions#
Here are the files we want to decrypt :
Decrypting .txt files#
Let’s start with the “.txt” files and extract the public key information from the client :
e = 3
n = 98364165919251246243846667323542318022804234833677924161175733253689581393607346667895298253718184273532268982060905629399628154981918712070241451494491161470827737146176316011843738943427121602324208773653180782732999422869439588198318422451697920640563880777385577064913983202033744281727004289781821019463
At first sight, there is nothing wrong with using a small public exponent for RSA as long as the data is big enough or properly padded. We also know that data is encrypted in chunks. Ideally the size of the chunk should be about the same as the size of the modulus. The modulus used here is 128 bytes long. Let’s open up IDA and see how big the chunk is.
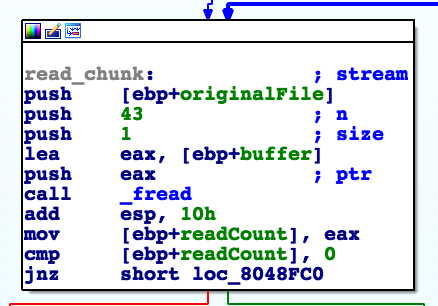
Each chunk is at most 43 bytes long, that’s far less than necessary. What happens if we take the biggest and smallest numbers of size 43 bytes, power 3 ?
a = "01"+"00"*42
(int(a,16)**3).bit_length()/8
# 126
a = "01"+"00"*43
(int(a,16)**3).bit_length()/8
# 129
For small 43 bytes numbers, the resulting number is smaller than the modulus. The consequence is that we can calculate the cube root of the ciphertext to obtain the plain text.
$c \equiv p^3 [n] \equiv (i*n + k) [n]$ with i=0
$c \equiv p^3$
$p \equiv c^{\frac{1}{3}}$
For the other case, the resulting number is a little bigger than the modulus :
$c \equiv p^3 [n] = (i*n + k) [n]$ with i>0
$c \equiv k$
$p \equiv (c+i*n)^{\frac{1}{3}}$
Because $p^3$ is relatively close to $n$, we can brute force until we find a valid value for $i$ that satisfies the equation :
$((c+i*n)^{\frac{1}{3}})^3 [n] = c$
We have almost everything we need in order to write a decryption script. We must now understand how the encrypted data was written in the file. Does it have a fixed length ?
Let’s look at the rsaEncrypt function.

The result of the modular exponentiation is transformed in hexadecimal using gmp_sprintf and the format string “%0256Zx”. This means that the output is padded with zeros until a size of 256 bytes. Once converted to a string this will be a chunk of 128 bytes every time.
Time to write the script.
# -*- coding: utf-8 -*-
import gmpy2
def ntos(x):
n = hex(x)[2:].rstrip("L")
if len(n)%2 != 0:
n = "0"+n
return n.decode("hex")
def ston(x):
n = x.encode("hex")
return int(n,16)
e = 3
n = 98364165919251246243846667323542318022804234833677924161175733253689581393607346667895298253718184273532268982060905629399628154981918712070241451494491161470827737146176316011843738943427121602324208773653180782732999422869439588198318422451697920640563880777385577064913983202033744281727004289781821019463
file = open("my_passwords.txt.ENO",'r').read()
blocks = [file[i:i+128] for i in range(0, len(file), 128)]
s = ""
for b in blocks:
bi = ston(b)
i = 0
r = gmpy2.iroot(bi + i*n, 3)[0]
while pow(r,e,n) != bi:
i += 1
r = gmpy2.iroot(bi + i*n, 3)[0]
print "i : ",i
s += ntos(r)
print s
$ python rsaDecryptor.py
i : 30
i : 37
i : 0
i : 43
i : 47
i : 29
i : 37
i : 25
i : 0
i : 27
i : 0
gmail:
- username : johnDoe
- password : n28e39ctw7v93cdhkw
facebook:
- username : theKiller98
- password : t4vhfijftwajsk9mta
twitter:
- username : J0hn D03
- password : 3qP6Wip5bGn9DskFVc
...
Decrypting .pdf files#
Now let’s look at the PDF encryption. We know it’s a xor on 256 bytes chunks . The key is retrieved from the C&C server at the beginning of each encryption. The key is modified after a block as been encrypted. The key modification algorithm is constant and only depends on the key itself.
The first thing to do is to find the key size. Let’s look at the size of the buffer passed to the getKey function.

The buffer is 8 bytes long but that’s not enough to be 100% sure about the key length. After all, the server could send a key longer then that and the client would accept it, as we saw in the first part. Let’s look at the strXor function.

Here the index for the key is restricted modulo 8, even if the key was longer, only the first 8 bytes would be used. Now we’re 100% sure that the length of the key is 8.
We could retrieve the key if we knew the first 8 bytes, after all it’s just a xor. Luckily, this encryption method is only applied on PDF files and as you may know, PDF files begin with 4 constant bytes followed by 4 bytes for the version, like this : “%PDF-1.5”
The only little uncertainty is on the version number, it could be “1.3” for example but that’s easily brute forceable.
If we retrieve the initial key thanks to known plaintext, we just need to apply the encryption algorithm once more to decrypt the file. Therefore, it’s important to reimplement the key schedule.
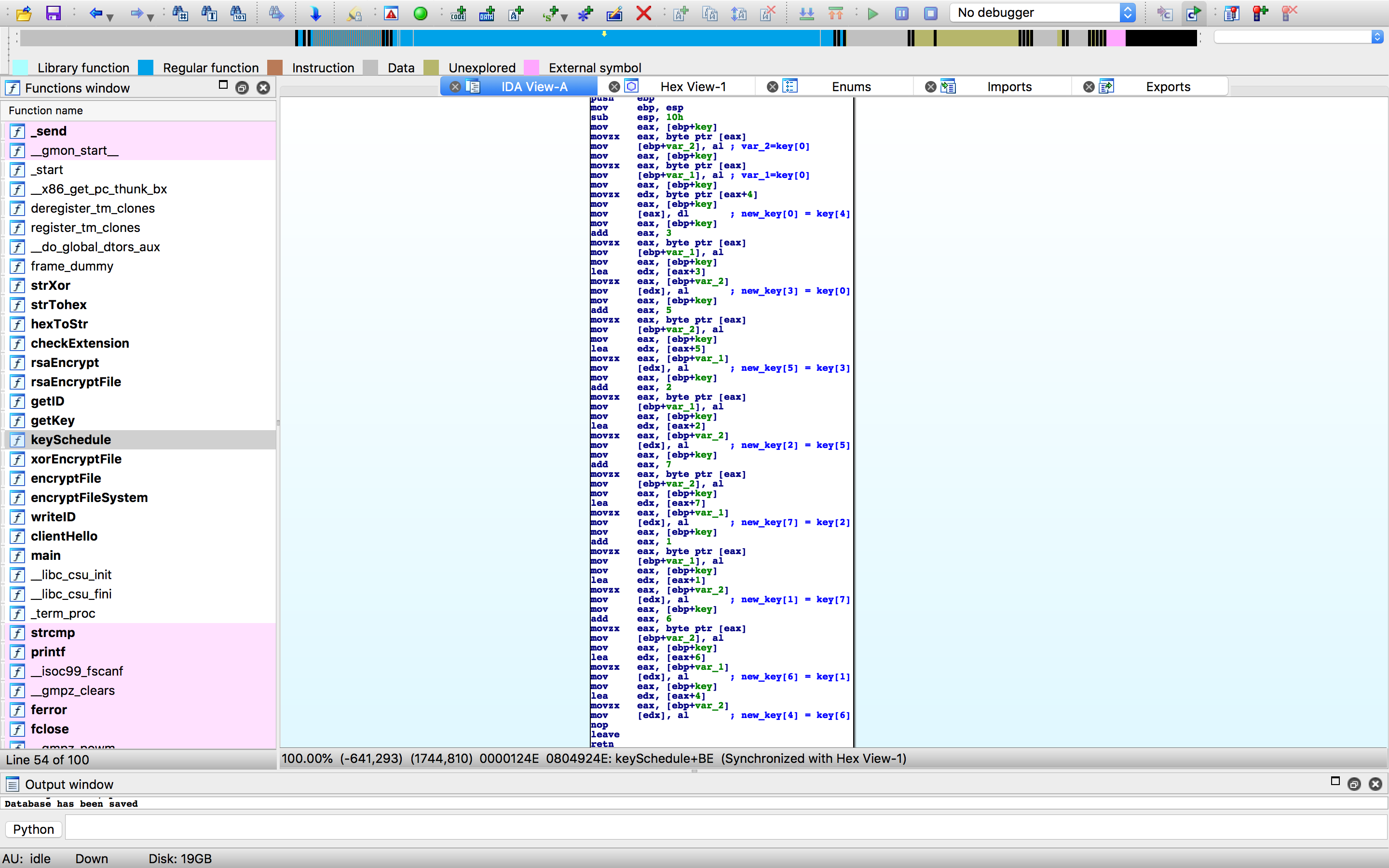
The key schedule is more a key mixing function and is easily reimplemented. We just need to write the script.
# -*- coding: utf-8 -*-
def strxor(a,k):
s = ""
for i in range(len(a)):
s += chr(ord(a[i])^ord(k[i%len(k)]))
return s
def mix(k):
out = list(k)
out[0] = k[4]
out[1] = k[7]
out[2] = k[5]
out[3] = k[0]
out[4] = k[6]
out[5] = k[3]
out[6] = k[1]
out[7] = k[2]
return "".join(out)
file = open("secret.pdf.ENO",'r').read()
blocks = [file[i:i+256] for i in range(0, len(file), 256)]
magic = "%PDF-1.3"
key = strxor(magic, blocks[0][:8])
s = ""
for b in blocks:
s += strxor(b, key)
key = mix(key)
open("decrypted.pdf","w").write(s)
This successfully decrypts the given pdf file :

In the next part we’re going to reverse engineer the Tupper server to better understand the communication protocol used with the client and try to find vulnerabilities that could allow remote code execution on the C&C server.